
【新智元导读】OpenClaw又迎重磅玩家!英伟达深夜带着Nemotron 3 Super炸场,1200亿参数专为Agent打造,性能直逼Claude Opus 4.6。推理狂飙3倍,模糊量猛涨5倍,「龙虾」这是要上天了。
宇宙市值一哥,也杀入OpenClaw战场了!
昨夜,英伟达重磅祭出新一代「开源模子」Nemotron 3 Super,专为大范围AI智能体打造。
它共有1200亿参数,120亿激活参数,100万token高下文,推理狂飙3倍,模糊量暴涨5倍。

Nemotron 3 Super袭取了创新的Mamba-MoE搀杂架构,绝对搞定了多Agent协同中的性能瓶颈。
何况,它一经「Nemotron 3家眷」中,首个已矣以下三大打破的模子:
原生袭取NVFP4精度进行预教师;
全新的LatentMoE搀杂巨匠架构,把「单元算力准确率」和「单元参数准确率」优化到了极致;
引入MTP(多Token估计)层,通过原生「投契解码」让推理速率狂飙。
在Pinchbench基准上,Nemotron 3 Super一骑绝尘,稳坐开源第一。
在OpenClaw任务成功率上,它拿下了85.6%的高分,性能直逼Claude Opus 4.6、GPT-5.4。

不错说,圆善适配OpenClaw的「最强开源模子」,降生了!
今天,Nemotron 3 Super高出10万亿Token的预教师和后教师数据集、完整教师门径论,以及15个强化学习环境全部开源。
地址:https://huggingface.co/collections/nvidia/nvidia-nemotron-v3

英伟达1200亿巨兽炸场
OpenClaw绝配
如今,聊天机器东谈主阶段迈向多Agent应用,频繁会装上「两堵墙」。
第一个是高下文爆炸。
多智能体责任流生成的Token数,比成例对话多出高达15倍。
因为每一次交互都需要再行发送完整的历史纪录,包括器具输出和中间的推理经过。
在履行长周期任务时,这种巨大的高下文数据量不仅推高了老本,还容易导致谈论偏移(goal drift),即逐步偏离了Agent最初设定的谈论。

第二个是「念念考税」(thinking tax)。
复杂的Agent必须在每一步都进行推理,但若是在每个子任务上都调用LLM,会让多Agent应用的老本,变得极其昂贵且响应迟缓,难以在履行应用中落地。
为此,英伟达开源的Nemotron 3 Super,绝对击碎了Agent应用的「两大桎梏」。

如上所述,Nemotron 3 Super领有100万Token高下文。
尤其是在运行OpenClaw环境下,AI能将扫数责任流情状完整保留在内存中,确保从第一步到终末一步的逻辑一致性。
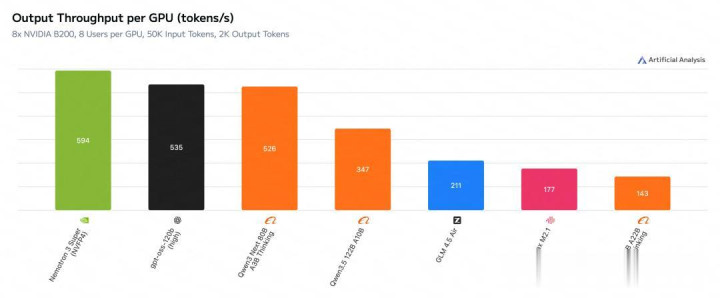
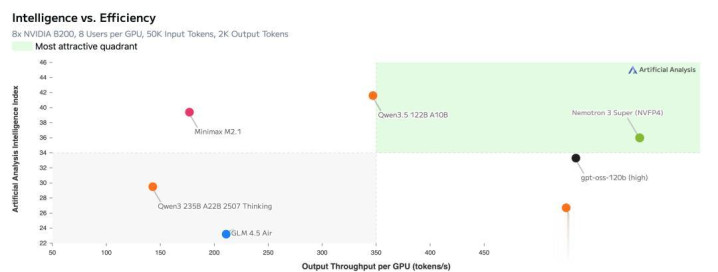
在Artificial Analysis上,Nemotron 3 Super刷新了SOTA,登上了效率和开源榜一。
在同等范围开源模子中,新模子准确率亦然遥遥最先。
同期,新模子加捏的NVIDIA AI-Q询查型AI智能体,在DeepResearch Bench 和 DeepResearch Bench II排名榜上拿劣等一。
未来五年,英伟达将干与260亿好意思元,用于打造宇宙顶尖的开源模子
搀杂架构翻新,模糊狂飙5倍
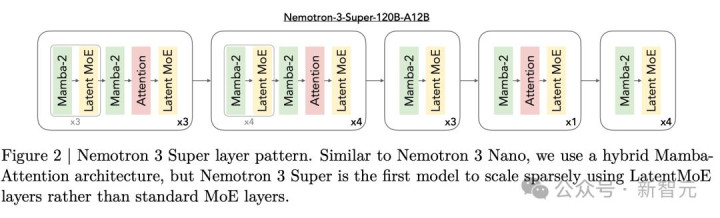
这一次,英伟达对Nemotron 3 Super底层架构进行了重构。
88层聚集袭取了周期性轮换陈设,其中Mamba-2层讲求高效的序列建模,提供线性时期复杂度。
而极少Transformer戒备力层则手脚「全局锚点」穿插其中,讲求跨位置的长距离信息路由和高精度推理。
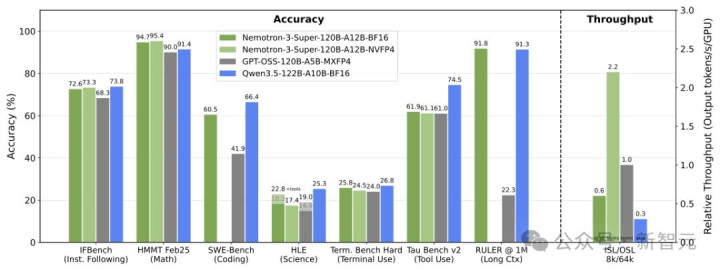
戒指,与上一代Nemotron Super模子比较,模糊量升迁高达5倍,准确率升迁高达2倍。
与GPT-OSS-120B、Qwen3.5-122B对比,Nemotron 3 Super均拿下了最高得益。
何况,在输入序列长度为8k、输出序列长度为64k时,它的模糊量区分比GPT-OSS-120B和Qwen3.5-122B高出多达2.2倍和7.5倍。

LatentMoE:懂硬件的巨匠联想,榨干每一字节的准确率
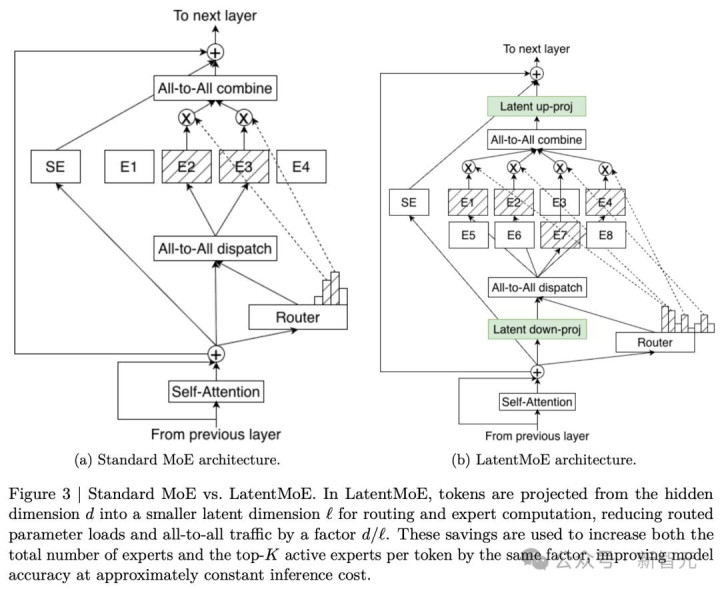
更紧迫的是,Nemotron 3 Super初次引入了「隐式MoE」(Latent MoE)。
LatentMoE的解法相当小巧,在路由和巨匠商量之前,先把Token从瞒哄维度d投射到一个更小的潜在维度ℓ。路由和巨匠商量都在这个小得多的维度里进行。
这意味着需要加载的巨匠参数和跨卡通讯量,径直减弱了d/ℓ倍!
省下来的这些资源,就不错用来把巨匠总和和每次激活的巨匠数放大相同的倍数。等于「白嫖」了一波准确率,而推理老本险些没变。
英伟达官方博客的说法更直不雅:花1个巨匠的商量老本,激活4个巨匠。
比较传统的MoE,LatentMoE在参数诓骗率和算力诓骗率上都更胜一筹。
多Token估计:性能+推理效率一矢双穿
Nemotron 3 Super还加入了一个大杀器:多Token估计(MTP),模子质地和推理效率一举两得。
传统的教师样式都是「估计下一个token」(Next-token),但MTP条目模子在每个位置上连气儿估计未来好几个 Token。
这其实是在逼着模子去交融多步之间的因果关系和更长期的文本结构。
事实讲解注解,这招相当管用,模子的考证集 Loss 和下贱跑分都迎来了实打实的升迁。
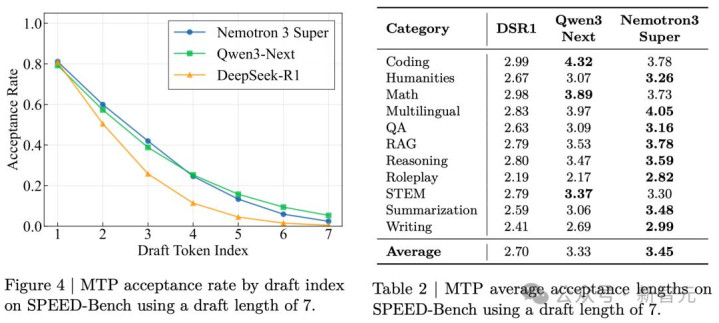
除了变贤惠,MTP最大的妙用是已矣了原生的投契解码(Speculative Decoding)。
{jz:field.toptypename/}这些独特的估计头就相当于在模子肚子里内置了一个「草稿模子(Draft model)」。
在推理时,估计头会先快速打个草稿(生成后续几个Token候选),然后主模子在一次前向传播中把这些草稿全部验算一遍。
这招大幅镌汰了生成蔓延,何况比较于外挂一个寂寥的草稿模子,开云体育它带来的独特算力支出(FLOPs)聊胜于无。
原生NVFP4精度预教师
正如英伟达询查副总Bryan Catanzaro所言,Nemotron 3 Super专为Blackwell联想。
预教师阶段,团队在Blackwell平台上全程使用NVFP4精度运行,显存需求大幅镌汰。
何况,在0准确率亏蚀的前提下,新模子的推理速率比Hopper架构上的FP8还要快4倍。

25万亿Token + 21个RL环境,对准AI智能体
和之前的Nemotron 3 Nano一样,Nemotron 3 Super亦然吃着25万亿Token文本数据长大的。
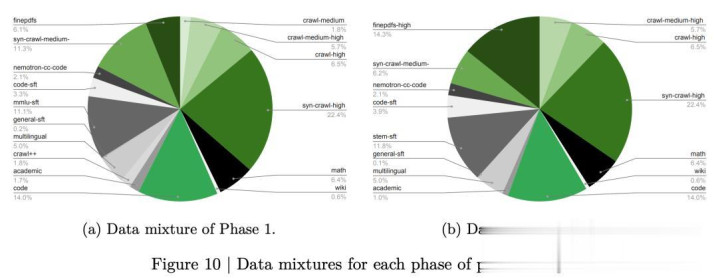
扫数预教师分为两步走:
第一阶段吃掉80%的数据(20万亿Token),主打一个数据各样性和常识面广,语料涵盖16个大类,从网页爬取到代码、数学、学术论文、多谈话数据一应俱全;
第二阶段吃掉剩下的20%(5万亿Token),这部分全是精挑细选的高质地数据,维基百科、高质地PDF、STEM推理数据的权重被大幅升迁,相当用来拉升准确率。
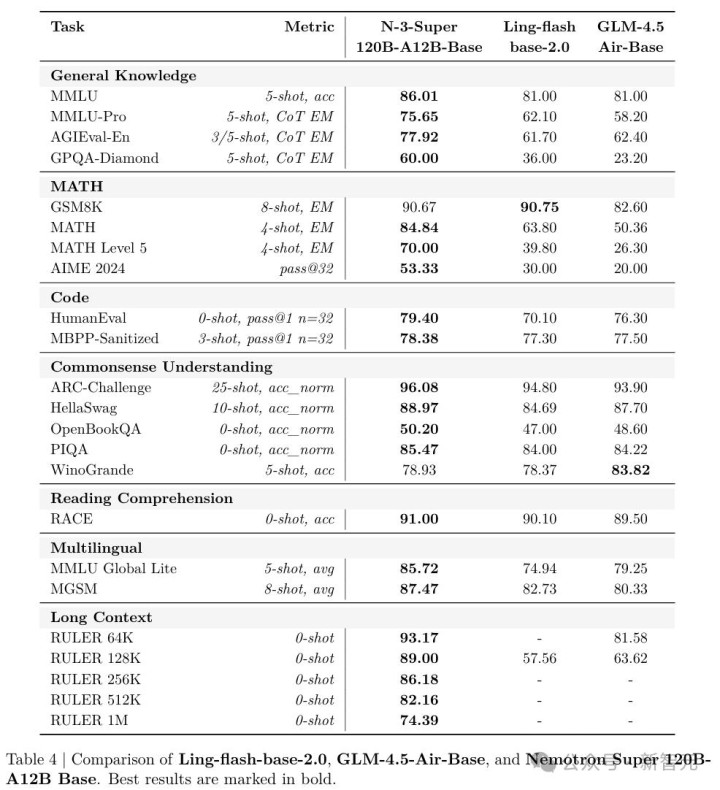
最终练出来的「基础模子」,在MMLU上跑到86.01,MMLU-Pro 75.65,MATH 84.84,把同等体量的顶流模子远远甩在了死后。
高下滑动张望
后教师方面,英伟达更是把技艺点狠狠点在了「AI智能体身手」上。
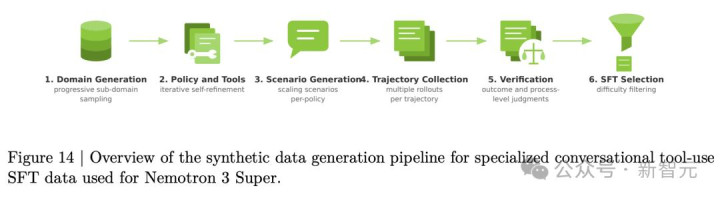
SFT阶段,教师了高出700万样本、800亿token。数据搀杂中,Agent关系任务占比高达36%,远超对话(23%)和推理(31%)。
Agent教师数据的范围升迁尤其凶猛。仅对话式器具调用一项,就从上一代Nano的5个规模、15,588条对话,暴涨到838个规模、279,116条对话。
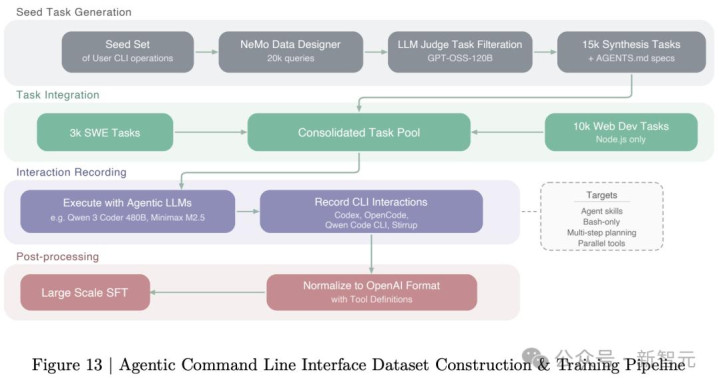
RL阶段更是大手笔,分四步走:
第一步,多环境RLVR。同期在21个环境、37个数据集上教师,粉饰数学、代码、STEM、安全、对话、辅导遵守、长高下文、谜题和各样Agent任务。每步采样256个prompt,每个prompt生成16个response。
第二步,SWE-RL。相当教师软件工程身手,干与20B token。每次rollout启动一个容器,在真是代码仓库中运行Agent轮回,生成代码补丁后用真是测试用例考证。
第三步,RLHF。18B token,教师了一个基于Qwen3-235B的GenRM奖励模子,在身份通晓和安全话题上精准调控步履。
第四步,MTP还原。冻结模子骨干,只教师MTP估计头,再行对皆投契解码的准确率。
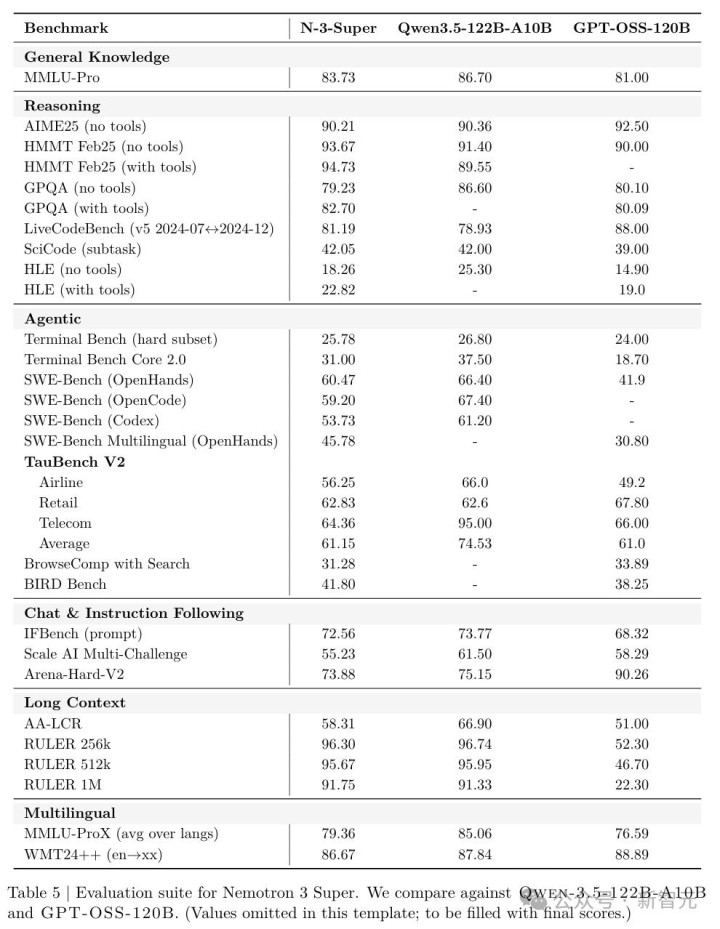
这套顶配的AI智能体教师秘籍效率何如?几个数字讲解一切:
SWE-Bench(OpenHands)上拿到60.47%,大幅高出GPT-OSS-120B的41.9%;
RULER@1M长高下文测试中达到91.75%,而GPT-OSS-120B独一22.3%;
AIME25数学推理上跑到90.21%,和Qwen3.5-122B的90.36%险些打平。
高下滑动张望
「龙虾」玩家赢麻了
数千页呈报秒进内存
Nemotron 3 Super高精度器具调用身手,不错让OpenClaw智能体在多个规模,已矣越过式进化。
在软件开拓中,AI智能体不错一次性将「扫数代码库」加载到高下文中。
无需繁琐的文档切分,即可已矣端到端的代码生成、罅隙建树与自动化调试。
在财务分析场景下,Nemotron 3 Super可将长达数千页的呈报径直加载到内存中。
这么一来,径直省去了在冗长对话中反复再行推理的穷苦,大幅升迁了责任效率。
凭借器具调用身手,Nemotron 3 Super还能让自主Agent在浩荡的函数库中可靠地导航操作,驻扎在诸如聚集安全规模的自主安全编排等高风险、要津环境中出现履行造作。
如今,一渊博玩龙虾的东谈主,不错径直用上了。
现在,Perplexity已接入Nemotron 3 Super供用户进行搜索,成为Computer中的20个编排模子之一。
还有CodeRabbit、Factory、Greptile提供软件开拓AI智能体的公司,已将其与自家模子集成到AI智能体中。
Edison Scientific和Lila Sciences等生命科学与前沿AI机构,也将用Nemotron 3 Super为其智能体提供算力赈济,用于深度文件检索、数据科学及分子结构交融。
英伟达版OpenClaw,要来了
光有模子还不够,英伟达此次连平台都一齐端上来了。
据WIRED爆料,英伟达正在高明打造一款名为NemoClaw的开源AI智能体平台,特大地向企业商场。
听这名字就知谈,「Nemo」对应Nemotron模子家眷,「Claw」直指OpenClaw。
翻译成东谈主话即是,英伟达要用自家模子,造一个企业级的OpenClaw。

跟OpenClaw的最大区别在哪?安全。
OpenClaw在个东谈主玩家手里玩得申明鹊起,但企业根底不敢碰。NemoClaw即是冲着这个痛点来的。
据报谈,NemoClaw从一启动就内置了一套安全和秘密器具,给企业吃省心丸。
何况它是完满开源的,无论你的系统跑的是不是英伟达芯片,都能用。
为什么要开源?逻辑很苟简。智能体用得越多,算力需求越大,英伟达照样赚。
Nemotron 3 Super是引擎,NemoClaw是底盘。模子+平台,双管皆下。
英伟达此次要给企业递上一套「开箱即用」的AI智能体全家桶。
OpenClaw让个东谈主玩家尝到了甜头,但企业商场这块蛋糕,英伟达通晓不野心让给任何东谈主。

 备案号:
备案号: