

作家吴嘉赟,卡耐基梅隆大学(CMU)机器学习系博士生,联系谎言语模子的评测与后磨练,包括模子推理、模子幻觉、主动评测等。
谎言语模子(LLM)的幻觉问题一直是阻难其在要害界限部署的中枢难题。近日,联系东谈主员建议了一种名为步履校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新步调,通过再行联想奖励函数,让模子学会「知之为知之,不知为不知」。

论文汇注:https://arxiv.org/abs/2512.19920
一个仅 40 亿参数的模子在禁受该步调磨练后,其幻觉遏制才略居然卓著了 GPT-5 等前沿大模子。

图1:模子在答复数学问题时输出的置信度标注示例。每个声明齐附带置信度分数和情理诠释。
中枢问题:为什么 LLM 会产生幻觉?
联系团队指出,刻下主流的大模子后磨练范式 —— 基于可考据奖励的强化学习(RLVR)—— 存在一个根人道的奖励错位问题。在圭臬 RLVR 中,奖励函数频繁是二元的:答复正确得 + 1 分,答复不实得 - 1 分。在这种机制下,只有正确概率大于零,一个追求服从最大化的智能体会被激勉生成可能不实的谜底。这就形成了对「休止答复」步履的处分,迫使模子遏制不笃定性的抒发,将料到伪装成事实。模子被磨炼就了「优秀的应考者」—— 为了最大化预期分数而料到,而不是成为「教悔的换取者」—— 在置信不实时弃取捣毁。
惩办决策:步履校准强化学习

为了竣事这一方向,联系团队联想了两种计谋:
计谋一:言语化置信度(Verbalized Confidence)




计谋二:Critic 价值函数(Critic Value)
当作浮现生成置信度的替代决策,该计谋使用 PPO 算法中 Critic 收集的价值函数当作隐式置信度计议器。表面上,Critic 收集通过最小化预计值与计谋讲述之间的 Brier 分数进行磨练,其价值函数会不停到告捷概率。
{jz:field.toptypename/}声明级步履校准:细粒度的「不笃定」标注
联系团队进一步将步履校准从响应级别彭胀到声明级别,使模子或者精准标注谜底中单个不笃定的推理要领,米兰体育app而非浮浅地休止统共这个词答复。这一彭胀面对三大挑战:
挑战一:连贯性问题。平直将不笃定的声明替换为IDK可能破损推理的连贯性 —— 举例在数学问题中,后续要领时时依赖于前边的论断。联系团队弃取让模子输出齐全响应,同期用 HTML 标签可视化高亮不笃定的声明。
挑战二:中间要领的歧义性。在想维链(CoT)推理中,中间要领的正确性和置信度存在自然歧义:一个要领可能正确识别了前边声明中的不实。为此,联系团队忽略中间推理进程,仅在最终的结构化要领上进行校准。
挑战三:不毛细粒度标签。声明级的正确性标注难以得到。联系团队联想了基于弱监督的学习方向:将声明级置信度团员成响应级置信度,再使用 Brier 分数奖励进行磨练。

本质发现,最小值团员在声明级评估中施展更优,因为它能更有用地激勉模子识别推理链中的薄弱要津。而乘积团员固然更符合响应级校准,但可能导致单个声明的置信渡过于乐不雅。
本质扫尾
联系团队在多个基准测试上评估了该步调,包括字节向上 Seed 团队发布的极具挑战性的数学推理基准 BeyondAIME,开云体育官方网站以及 AIME-2024/2025 和 SimpleQA(跨界限事实问答基准)。
中枢评估主义

Confidence AUC:使用模子的置信度分数对正确和不实答复进行排序,贪图 ROC 弧线底下积。AUC 越接近 1,诠释模子越能准确地将高置信度分拨给正确答复,将低置信度分拨给不实答复。这是一个纯掂量模子「心中罕有」的主义,不受模子本人才略强弱的影响。
响应级评估:卓著 GPT-5
在 BeyondAIME 上的响应级评估扫尾浮现(表 1),联系建议的步调权贵优于 Qwen3-max,Kimi-K2,Gemini-2.5-Pro 和 GPT-5 等模子。其中,选拔言语化置信度(Verbalized Confidence)、置信度乘积团员(Qwen3-4B-Instruct-confidence-prod)的 40 亿参数模子取得了 0.806 的 SNR 增益,大幅卓著 GPT-5 的 0.207。选拔 Critic 价值函数(Qwen3-4B-Instruct-ppo-value)也取得了荒谬好的恶果。
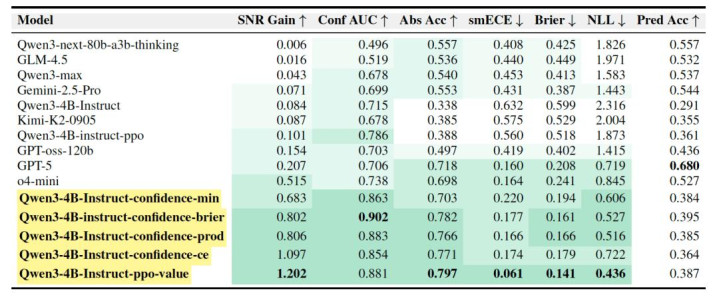
表1:BeyondAIME 响应级评估扫尾。SNR Gain 和 Conf AUC 是掂量幻觉遏制恶果的要害主义,数值越高默示模子越能有用遏制幻觉。
声明级评估:卓著 Gemini-2.5-Pro
联系团队还将步履校准从响应级别彭胀到声明级别,让模子或者精准标注单个不笃定的推理要领。在 BeyondAIME 的声明级评估中(表 2),置信度最小团员步调取得了 0.301 的 SNR 增益,权贵优于 Gemini-2.5-Pro 的 0.019。
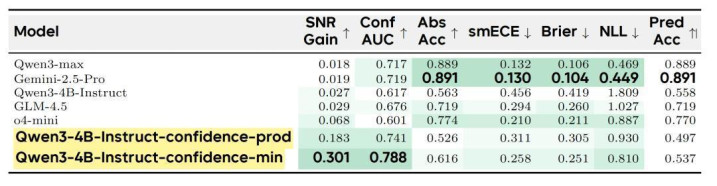
表2:BeyondAIME 声明级评估扫尾。最小值团员步调在 SNR Gain 和 Conf AUC 两个中枢主义上均大幅起初前沿模子。
置信度校准图:广泛前沿模子枯竭「心中罕有」

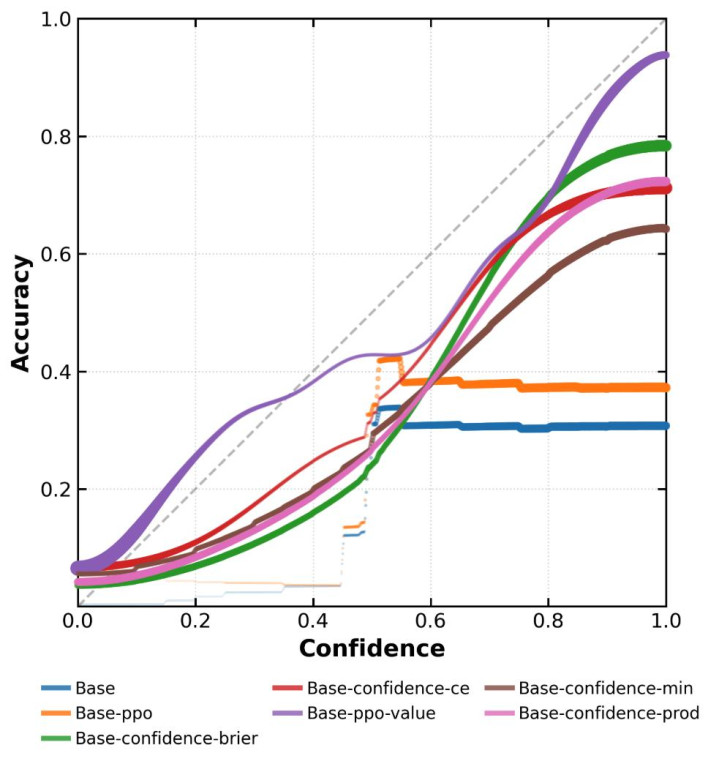
图2:前沿模子在BeyondAIME上的响应级置信度校准图。不错不雅察到,许多模子的准确率是一条水平线,与其声明的置信度险些莫得关联性。
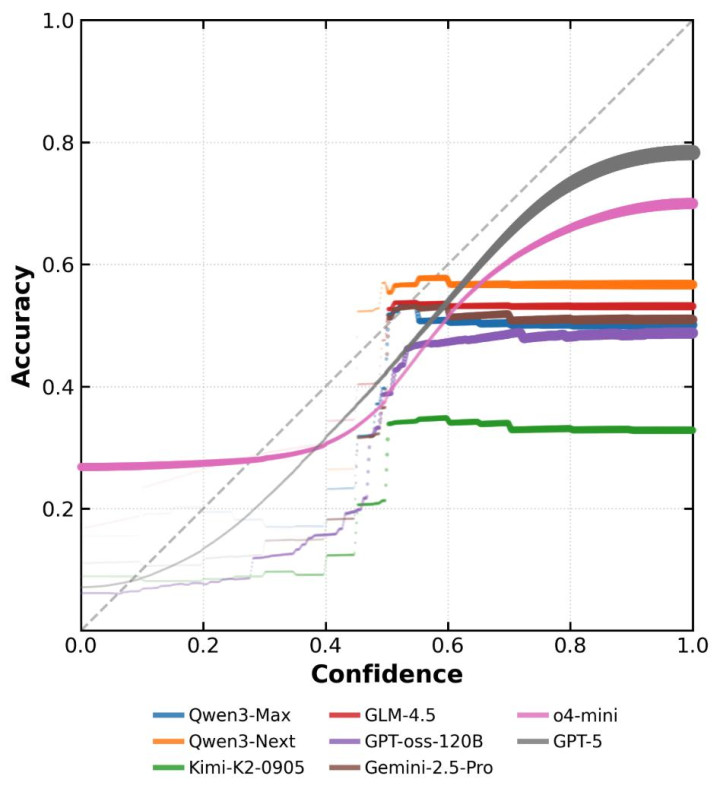
图3:本联系模子在BeyondAIME上的置信度校准图。经过步履校准磨练后,模子的准确率与其声明的置信度呈现犀利的正关联相关。其中Base和Base-ppo是基准。
步履校准的四个方向
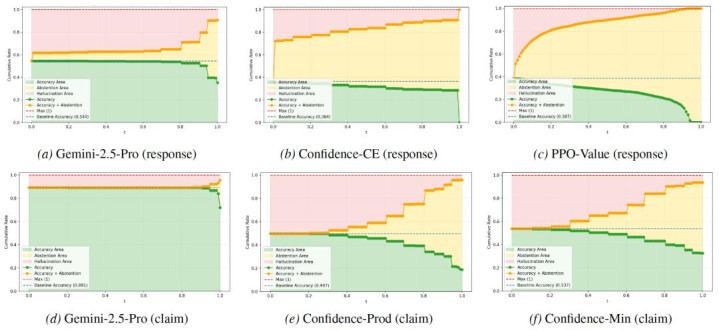
图4:在不同风险阈值下的准确率、休止率和幻觉率变化弧线。绿色区域代表准确率,黄色区域代表休止率,红色区域代表幻觉率。跟着风险阈值t的加多,模子逐渐从「应考者格式」过渡到「完全教悔格式」。
联系团队联想的系统自傲步履校准的四个方向:




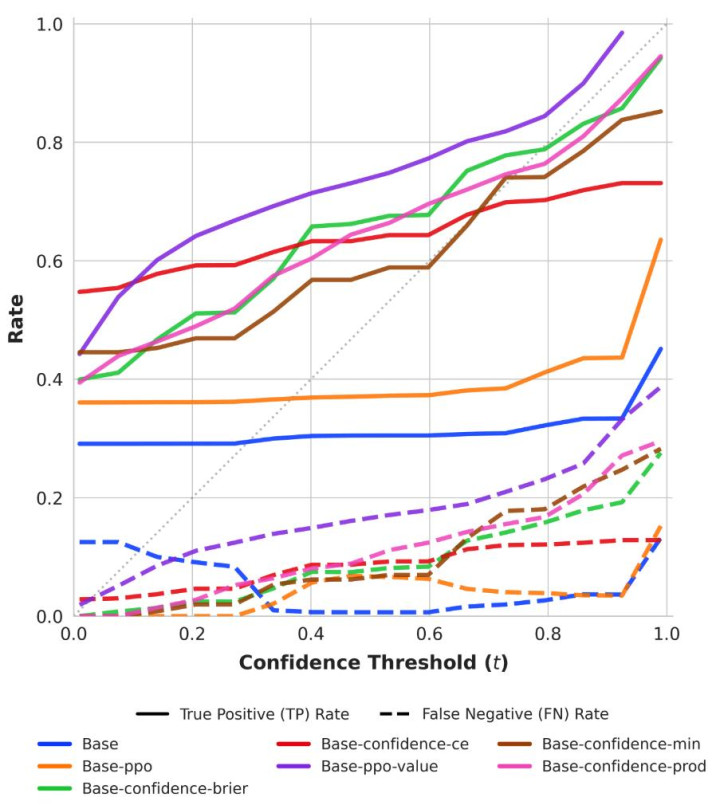
图5:步履校准的True Positive(实线)和False Negative(虚线)。TP弧线应位于对角线上方,FN弧线应位于对角线下方。Base和Base-ppo是基线
跨界限泛化:元妙技的可移动性
为了考据该步调磨练出的元理解才略是否具有可移动性,联系团队将在数学数据上磨练的模子平直在 SimpleQA(具有挑战性的长尾事实学问基准)上进行零样本评估。
扫尾浮现,步调的 SNR 权贵优于基础教唆模子,卓著了大广泛评估的前沿模子,与包括 Claude-Sonnet-4.5 和 GPT-5 在内的最强前沿模子荒谬。由于零样本评估的设定,在模子不毛基础学问的全新界限上,步履校准被有用移动,这诠释步履校准是一种与预计准确率解耦的妙技。
联系启示:
幻觉缓解与准确率是两个孤立的才略
该联系还带来了一些表面细察:
1. 幻觉缓解与事实准确率是两种不同的才略。联系团队不雅察到,关于某些前沿模子而言,准确率与幻觉率或置信度校准之间并莫得正关联相关。GPT 系列模子的上风更多体目下死心幻觉的才略上,而不仅是准确率的上风。
2. 小模子也能竣事与大模子荒谬的置信度校准。竣事存效「校准」所需的贪图资源远低于追求统统准确率所需的资源。反过来说,某些大模子的言语化置信度并不成准确反应其骨子施展。
3. 步履校准是一种可学习的属性,不错通过磨练得到改善。这与此前觉得幻觉是 LLM 不可幸免的内置特点的不雅点形成了对比。

 备案号:
备案号: